运维工作中自动化巡检的必要性以及重要性
一、为什么要进行巡检
- 当前平台架构复杂,中间件繁多,组件之间耦合度高,微服务还未达到故障自愈水平,所以需要通过告警或巡检等手段发现问题来保障平台持续稳定运行。
- 当前有客户对平台及上层应用使用频率低,例如三四天登录查看一次数据,但是设备是正常运转的,一旦平台出现问题,刚好客户发现问题,运维 才去解决就为时已晚。
- 定期巡检方案是模拟人工登录各业务页面,而非接口调用,更能真实地发现问题,并通过截图真实保留平台运行状态。
- Prometheus平台的监控报警功能还未覆盖到整个业务系统,部分问题还未能实时监控到,导致平台出现异常后而无法感知。
- 当前并不能保证客户环境的Prometheus平台本身不存在问题,针对这种不确定性,定期巡检是一个保障平台稳定性的方案,实现平台双保障。
- 部分客户环境不能够连接外网,Prometheus的监控告警信息无法同步到微信、飞书等,但可以通过定期巡检方案来保障平台稳定运行。
由于以上原因,为了保证SLA,必须进行定期巡检。
二、巡检检查项
2.1 服务器基础信息
cpu 利用率
磁盘利用率
内存利用率
服务器时间同步
日常数据备份文件检查
2.2 k8s集群状态
证书过期检查
API通信是否正常
各名称空间下的pod运行状态
ceph共享存储是否正常
2.3 业务状态
业务平台登录是否正常
kafka是否积压
kafka消费速率
三、实现方式
前期:前期巡检同事登录各客户环境进行人工手动巡检(登录VPN、连接跳板机、登录业务平台、登录grafana平台等等)一些列操作下来,一轮巡检工作大约在2-3hours。
目前:通过自动化的方式(shell+python+web框架flask)实现了,人工在windows跳板机上、Linux服务器中的模拟人工操作连接VPN、登录业务平台、登录grafana平台等一系列操作,定期定时将巡检任务结果发送至企业微信群内;从单人单次巡检的2-3小时,直接提效到了5-10min,极大程度上提高了日常巡检的工作效率。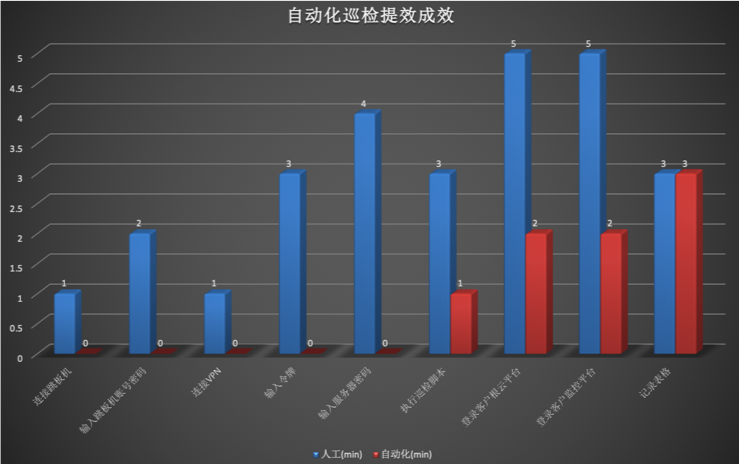

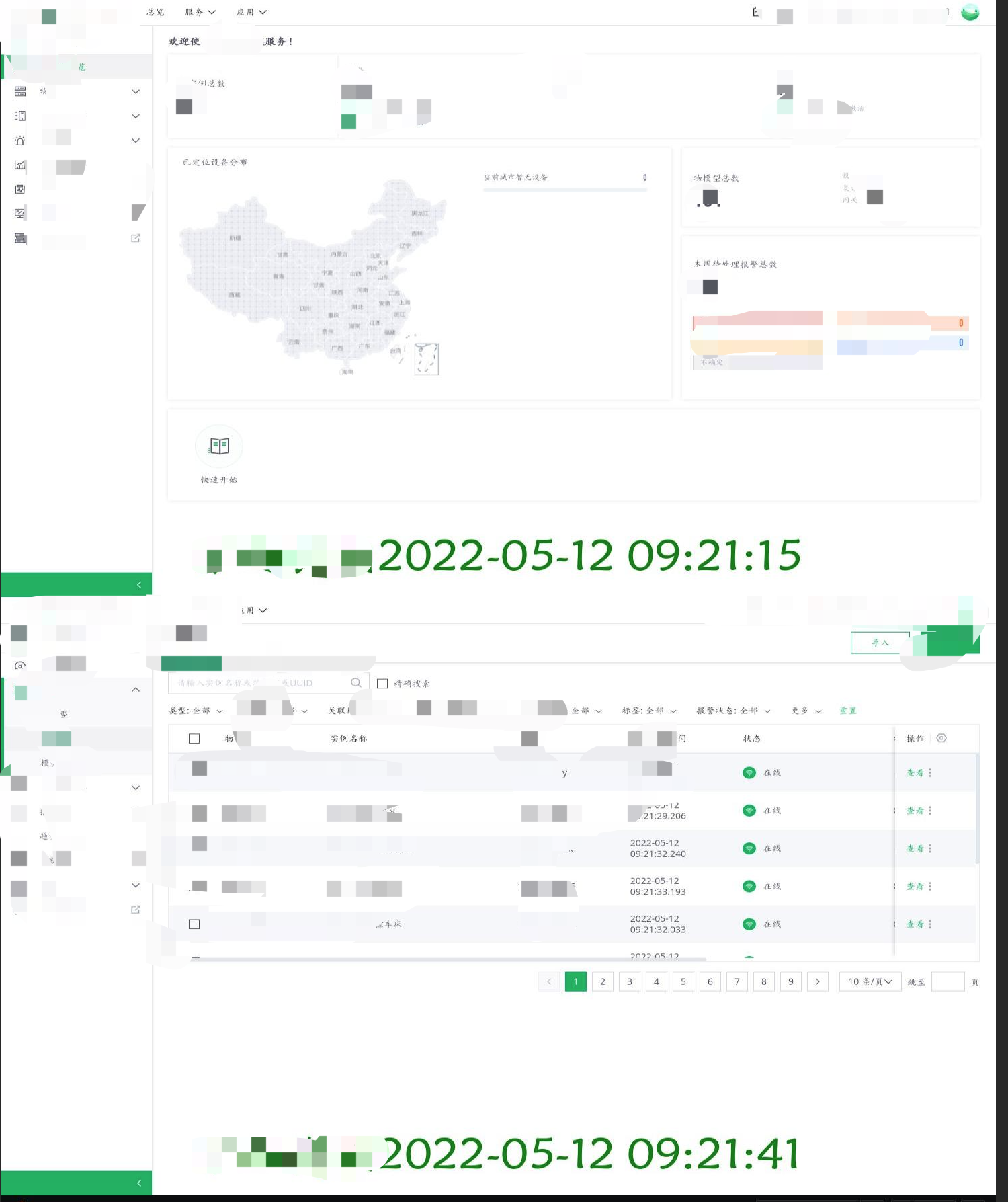
那么,在客户环境数量达到一定体量时,群消息接收也会造成巡检遗漏的情况,在这种情况下需要一个集中化的平台作为展示,于是将巡检结果发送到群内的同时也会将消息格式化(注:图片是通过Python截图生成后将其转换为base64编码,然后将其他巡检结果内容格式化为json后post到web后端,再在web前端进行展示)
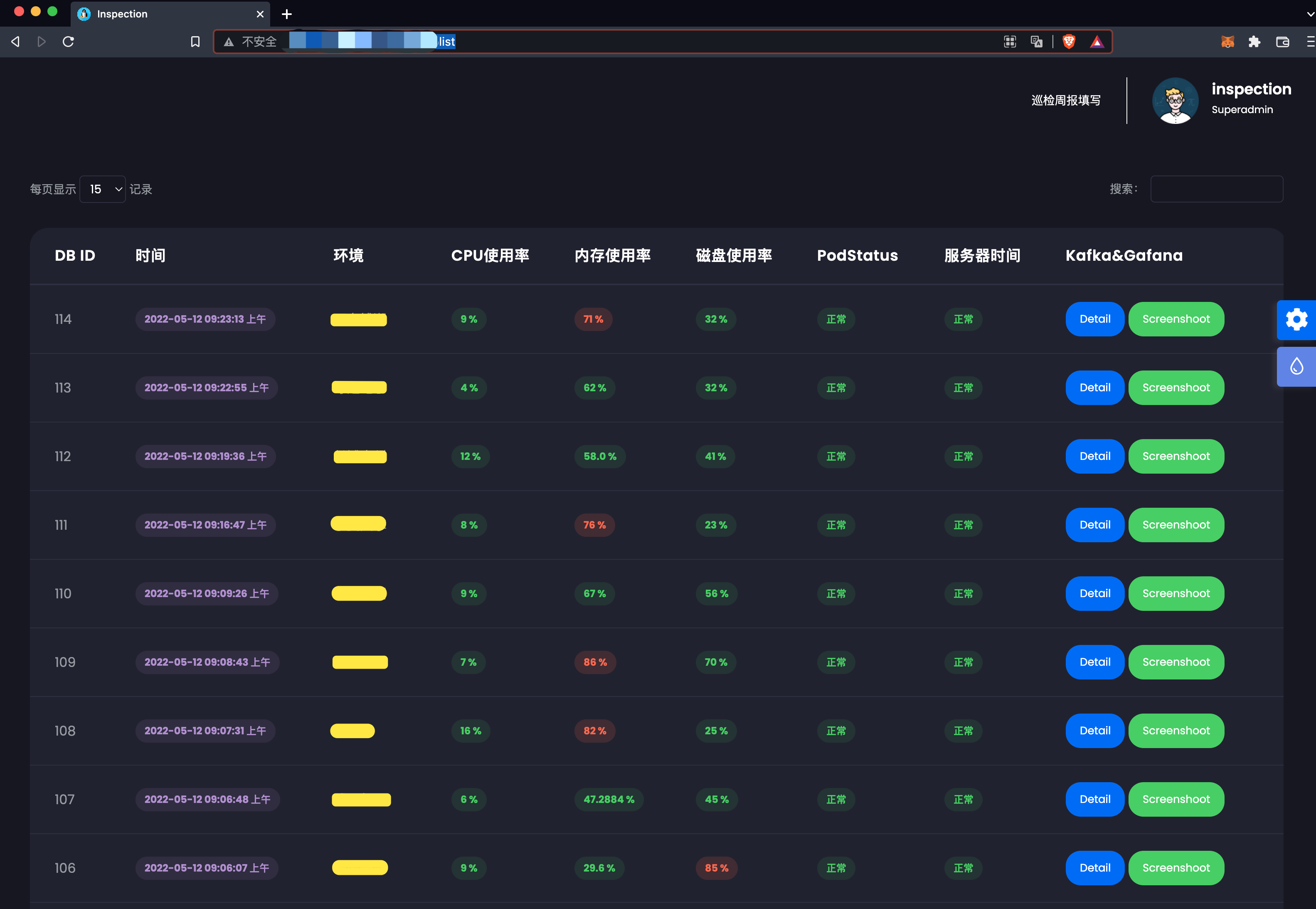
Detail: 通过点击后弹出整个巡检过程以及结果信息;
Screenshoot: 通过点击后将会弹出base64编码转换为图片的业务平台及grafana截图
最后,巡检人员只需要定期浏览此汇总展示平台即可!
(人工操作是基础,自动化操作才是王道😀 )
技术点
- Python自动化
- Selenium爬虫技术(网页内容获取)
- Windows端UI自动化(用于自动启动VPN程序,并填写账号密码后进行登录操作)
- Flask前后端开发(平台展示,内容接收入库)
- 企业微信机器人Webhook集成
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 OpsThoughts!
 wechat
wechat alipay
alipay
相关推荐

2016-12-16
"Devops" Demo(如果文中图片显示不完整,请多次刷新)
今年断断续续在工作之余学习了一下 Python Web框架,下面简要说下学的东西主要有以下几个: Flask(包括各个子系统组件) + Bootstrap主要是第一个接触的就是Flask这个框架,期初给我的感觉就是开发起来非常的快捷、方便,各个子系统也有单独的学习资料,所以从一开始我也就一直断断续续的在折腾;Bootstrap DiaoBao了. SaltStack API(netapi/rest_cherrypy)这个就不用说了吧,运维人都知道;在掌握了SaltStack在命令行的用法之后就需要去学习、探索更多更便利的方法来实现我们想要的效果; Zabbix API监控利器 zabbix, 更不用说了。由于工作上的所需,增减服务器是常有的事,那怎么快速的去添加/删除主机呢,当然就要让接口帮忙去处理啦; 下面是demo的雏形:登录系统使用的是Flask自带的Flask-Login组件,验证码用的是Google的ReCAPTCHA,当然这个在Flask表单中已经集成了;  SaltStack 命令执行,调用的是SaltApi,这里需要手动填写主机名,是个需要优化的地方. 当...

2018-03-08
如何利用Git Webhook 进行部署
作为一名”伪码农”运维工程师,在接触了开发方面的知识后;也在写项目时一直使用git,可是开发、调试、部署都是在本地进行的;在部署到服务器时也是通过手工去获取仓库的代码;1.开发完代码提交到远程仓库;2.登录远程服务器,并切到代码目录进行git pull;3.重启supervisor应用(我这边开发的python web应用是supervisor进行管理); 当然如果只是一次性部署上去就不再修改的话并没啥问题,但是要是项目持续性修改迭代的话,就比较麻烦了,就在不断的重复着上面的步骤。作为一个”伪码农”,怎么允许不断的重复同样的工作,于是git webhooks闪亮登场;大家对于钩子并不陌生,同样的版本控制SVN也有钩子这个功能;只是个人更加的倾向于使用git; 然后git也催生出来了很多;比如使用最广泛的是GitHub,再其次就是Gitlab,最后就是我这边是用的Gogs;他们都有同样的功能;只是说看需求跟习惯; gogs有个docker版本;能在2分钟之内就可以跑起来非常轻巧方便;感兴趣的请点击这里Gogs git webhook进行自动部署如何实现 Git webhook进行自...

2017-11-24
如何使用Celery(芹菜)异步神器执行后台任务
关于异步的知识网上很多,这里就直接上代码,目前结合Flask这个Python框架实现后台任务的执行操作; 1.需要了解的知识点: 了解生产消费模型或者发布订阅模式来实现消息队列 了解异步、同步之间的差别 2.实现过程(1)目录结构├── LICENSE ├── README.md ├── app // Flask APP应用 │ ├── __init__.py │ ├── auth │ ├── email.py │ ├── main │ ├── models.py │ ├── salt │ ├── static │ └── templates ├── config.py // 通用配置 ├── config.pyc ├── manager.py ├── migrations │ ├── READM...



