如何让添加定时作业任务变得更加优雅

序 APSCheduler 简介
在平常的工作中有些工作都需要定时任务来推动,例如项目中有一个定时刷新排行榜的程序脚本、定时爬出网站的URL程序、定时检测钓鱼网站的程序等等,都涉及到了关于定时任务的问题;虽然这些定时任务在服务器上面都能通过crontab来做;其次想到的是利用time模块的time.sleep()方法使程序休眠来达到定时任务的目的,虽然前两者也可以,但是总觉得不是那么的专业,😁所以就找到了python的定时任务模块APScheduler;
APScheduler基于Quartz的一个Python定时任务框架,实现了Quartz的所有功能,使用起来十分方便。提供了基于日期、固定时间间隔以及crontab类型的任务,并且可以持久化任务。基于这些功能,我们可以很方便的实现一个python定时任务系统。
同时APScheduler还提供了Flask的扩展Flask-Apscheduler, 那正好就可以拿来做一个集成定时任务平台;
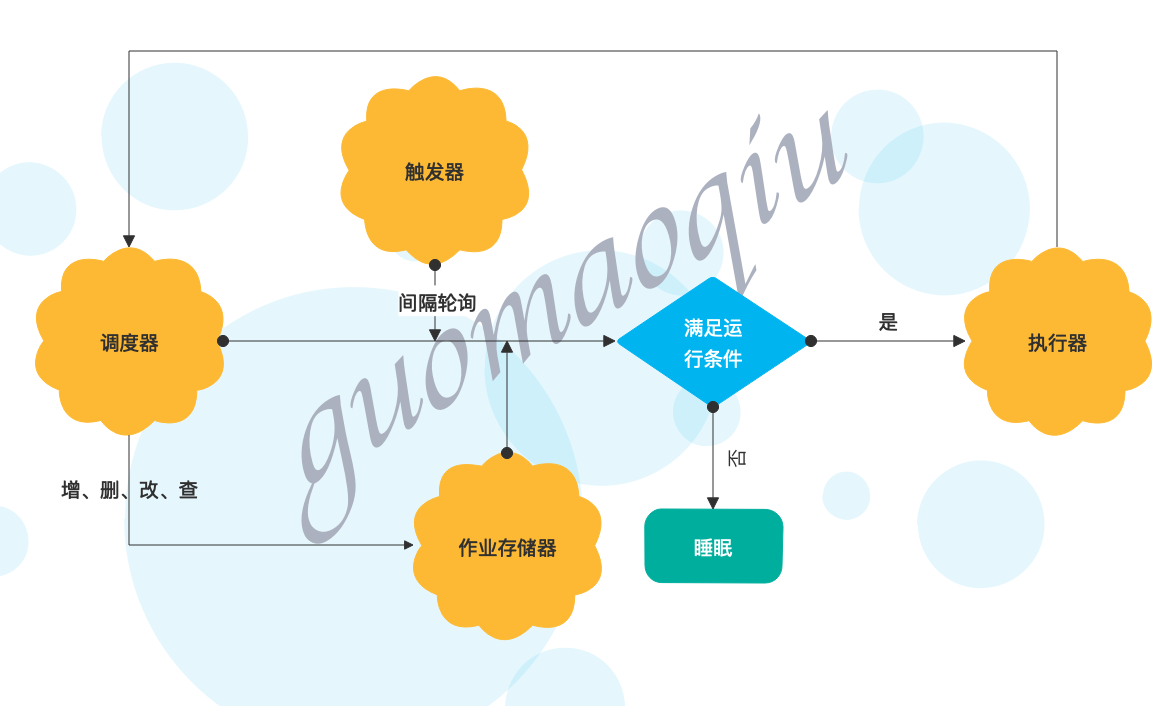
APScheduler有四个组成部分
触发器(trigger)包含调度逻辑,每一个作业有它自己的触发器,用于决定接下来哪一个作业会运行。除了他们自己初始配置意外,触发器完全是无状态的。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38cron: 类linux下的crontab格式,属于定时调度
interval:每隔多久调度一次
date:一次性调度
#1. cron风格
(int|str) 表示参数既可以是int类型,也可以是str类型
(datetime | str) 表示参数既可以是datetime类型,也可以是str类型
year (int|str) – 4-digit year -(表示四位数的年份,如2008年)
month (int|str) – month (1-12) -(表示取值范围为1-12月)
day (int|str) – day of the (1-31) -(表示取值范围为1-31日)
week (int|str) – ISO week (1-53) -(格里历2006年12月31日可以写成2006年-W52-7(扩展形式)或2006W527(紧凑形式))
day_of_week (int|str) – number or name of weekday (0-6 or mon,tue,wed,thu,fri,sat,sun) - (表示一周中的第几天,既可以用0-6表示也可以用其英语缩写表示)
hour (int|str) – hour (0-23) - (表示取值范围为0-23时)
minute (int|str) – minute (0-59) - (表示取值范围为0-59分)
second (int|str) – second (0-59) - (表示取值范围为0-59秒)
start_date (datetime|str) – earliest possible date/time to trigger on (inclusive) - (表示开始时间)
end_date (datetime|str) – latest possible date/time to trigger on (inclusive) - (表示结束时间)
timezone (datetime.tzinfo|str) – time zone to use for the date/time calculations (defaults to scheduler timezone) -(表示时区取值)
#如:在6,7,8,11,12月份的第三个星期五的00:00,01:00,02:00,03:00 执行该程序
sched.add_job(my_job, 'cron', month='6-8,11-12', day='3rd fri', hour='0-3')
#2.interval风格
weeks (int) – number of weeks to wait
days (int) – number of days to wait
hours (int) – number of hours to wait
minutes (int) – number of minutes to wait
seconds (int) – number of seconds to wait
start_date (datetime|str) – starting point for the interval calculation
end_date (datetime|str) – latest possible date/time to trigger on
timezone (datetime.tzinfo|str) – time zone to use for the date/time calculations
#如:每隔2分钟执行一次
scheduler.add_job(myfunc, 'interval', minutes=2)
#3.date风格
run_date (datetime|str) – the date/time to run the job at -(任务开始的时间)
timezone (datetime.tzinfo|str) – time zone for run_date if it doesn’t have one already
#如:在2009年11月6号16时30分5秒时执行
sched.add_job(my_job, 'date', run_date=datetime(2009, 11, 6, 16, 30, 5), args=['text'])作业存储(job store)存储被调度的作业,默认的作业存储是简单地把作业保存在内存中,其他的作业存储是将作业保存在数据库中。一个作业的数据讲在保存在持久化作业存储时被序列化,并在加载时被反序列化。调度器不能分享同一个作业存储。jobstore则是指的是job持久化,默认job运行在内存中,可持久化在数据库,指定为mongo的MongoDBJobStore或者是使用sqlite的SQLAlchemyJobStore,同时可指定多种jobstore
执行器(executor)处理作业的运行,他们通常通过在作业中提交制定的可调用对象到一个线程或者进城池来进行。当作业完成时,执行器将会通知调度器。说白了就是指定任务是以线程池/进程池里运行,这在初始化时可以指定,同时可以指定最大的工作池,默认的为default: ThreadPoolExecutor,max-worker为20,当然也可以指定为processpool,默认max-worker为5
调度器(scheduler)是其他的组成部分。你通常在应用只有一个调度器,应用的开发者通常不会直接处理作业存储、调度器和触发器,相反,调度器提供了处理这些的合适的接口。配置作业存储和执行器可以在调度器中完成,例如添加、修改和移除作业。
调度器分为以下几种,可根据不同的使用场景选用不同的调度器:1
2
3
4
5
6
7BlockingScheduler: 很明显这是种阻塞型,一般用在没有其它进程运行的场景下
BackGroundScheduler: 后台式,也就是单起一个进程/线程运行该任务,不影响主程序
ASyncIOScheduler:
GeventScheduler:
TornadoScheduler:
TwistedScheduler:
QtScheduler:本人只使用过BlockingScheduler跟BackGroundScheduler,flask-scheduler使用的即为BackGroundScheduler,其它的后续再研究研究
选择类型也很简单,初始化时直接实例化:1
2
3
4from apscheduler.schedulers.background import BackgroundScheduler
scheduler = BackgroundScheduler()
#启动
scheduler.start()
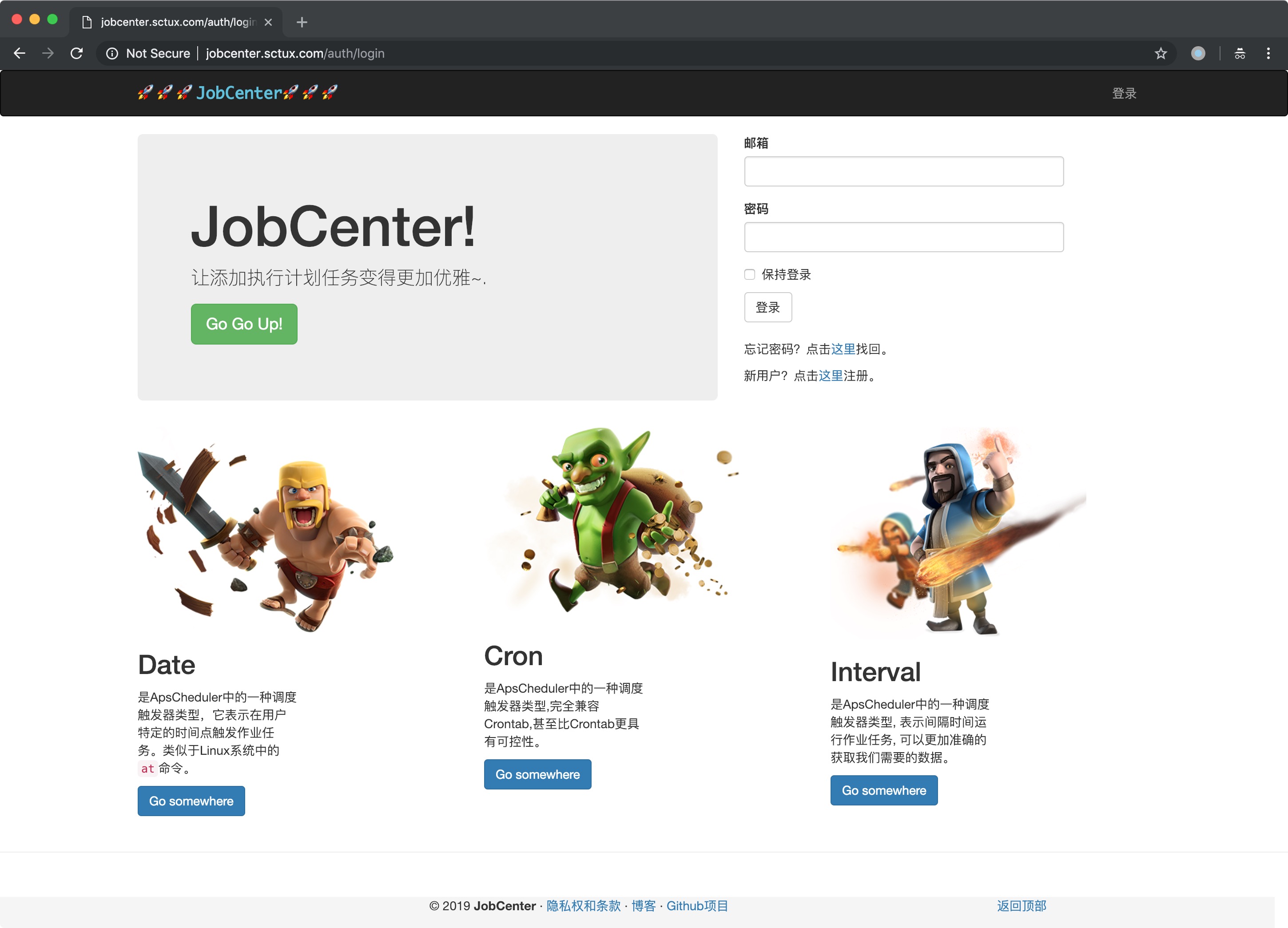
以上就是apscheduler主要组成的四个方面。那么既然有提供flask-apscheduler这个扩展,那一定是把apscheduler封装过后为我们提供更加方便的集成开发,这里我的存储选择了MySQL作为作业任务存储,因为我这里的平台的用户是用它来存储的;为了方便统一使用了MySQL;
以下是这个项目的结构:
1 | /data/study/github_repo/JobCenter $ tree -L 2 |
目前主要实现的功能有:
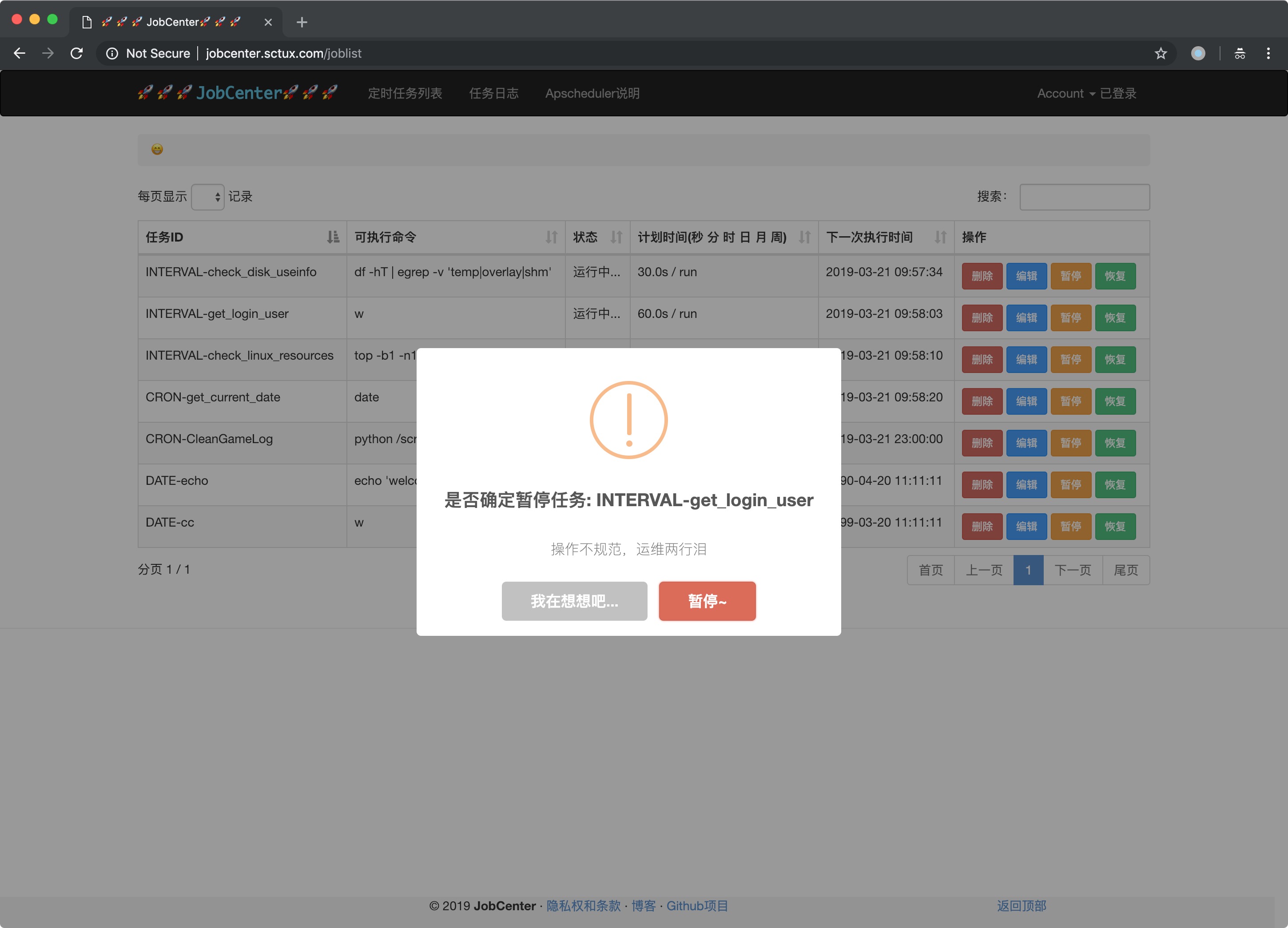
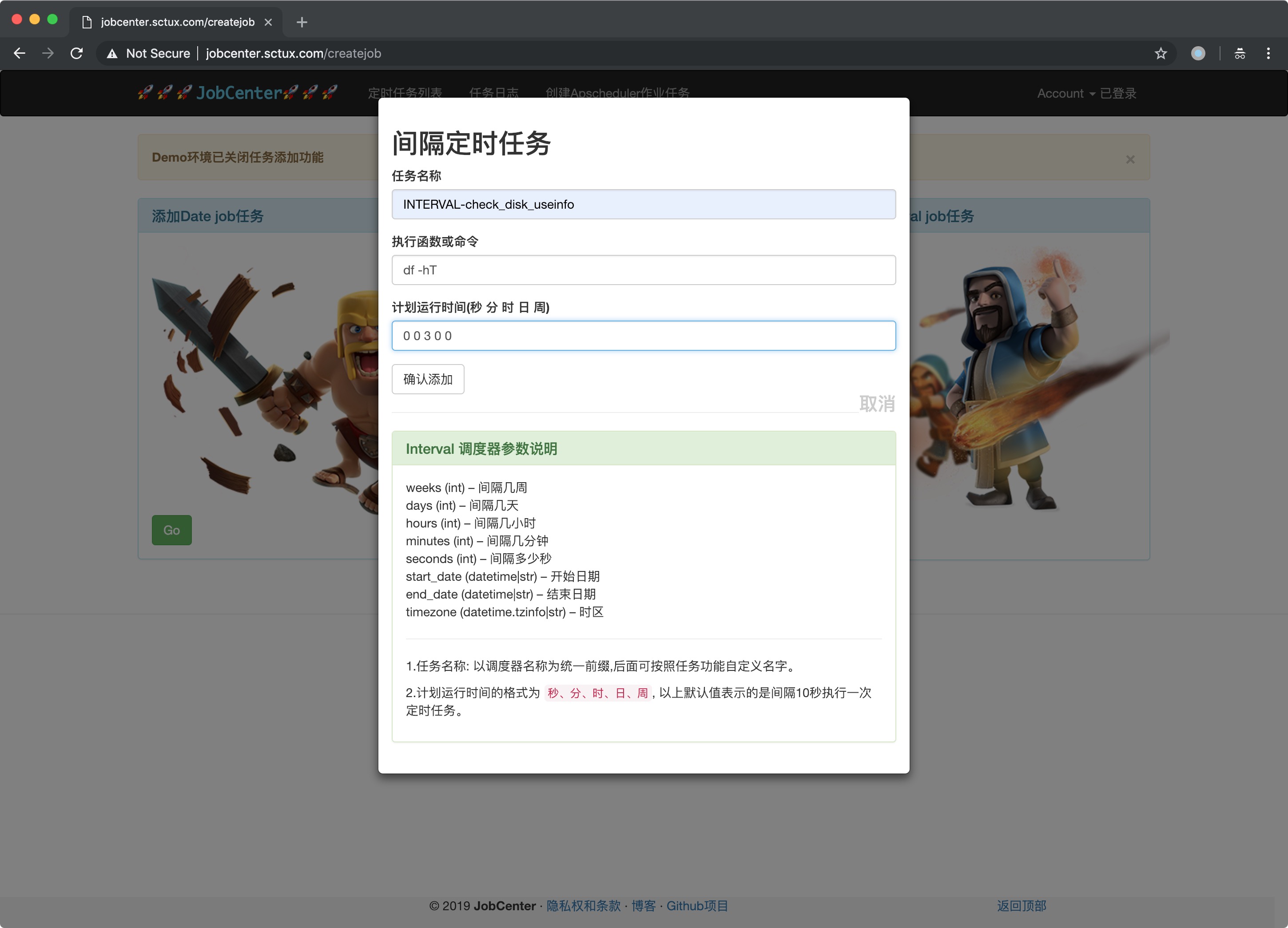
- 可视化界面操作
- 定时任务统一管理
- 完全兼容Crontab
- 支持秒级定时任务
- 作业任务可搜索、暂停、编辑、删除
- 作业任务持久化存储、三种不同触发器类型作业动态添加
欢迎star 欢迎提建议~
项目地址: https://github.com/guomaoqiu/JobCenter
Demo地址: https://jobcenter.sctux.cc
 wechat
wechat alipay
alipay





