概述 当你使用kuberentes的时候,有没有遇到过Pod在启动后一会就挂掉然后又重新启动这样的恶性循环?
本博文主要记录实践如何配置容器的存活和就绪探针。
liveness probe(存活探针)
readiness probe(就绪探针)
每类探针都支持三种探测方法
exec:通过执行命令来检查服务是否正常,针对复杂检测或无HTTP接口的服务,命令返回值为0则表示容器健康。
httpGet:通过发送http请求检查服务是否正常,返回200-399状态码则表明容器健康。
tcpSocket:通过容器的IP和Port执行TCP检查,如果能够建立TCP连接,则表明容器健康。
每种方式都可以定义在readiness 或者liveness 中。比如定义readiness 中http get 就是意思说如果我定义的这个path的http get 请求返回200-400以外的http code 就把我从所有有我的服务里面删了吧,如果定义在liveness里面就是把我kill 了。
探针探测的结果有以下三者之一
Success:Container通过了检查。
Failure:Container未通过检查。
Unknown:未能执行检查,因此不采取任何措施。
重启策略
Always: 总是重启
OnFailure: 如果失败就重启
Never: 永远不重启
LivenessProbe探针配置 示例一: 通过exec方式做健康探测 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 exec-liveness.yaml apiVersion : v1 kind : Pod metadata : labels : test : liveness name : liveness-exec spec : containers : - name: liveness image : k8s.gcr.io/busybox args : - /bin/sh - -c - touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600 livenessProbe : exec : command : - cat - /tmp/healthy initialDelaySeconds : 5 periodSeconds : 5
在该配置文件中,对容器执行livenessProbe检查,periodSeconds字段指定kubelet每5s执行一次检查,检查的命令为cat /tmp/healthy,initialDelaySeconds字段告诉kubelet应该在执行第一次检查之前等待5秒,
当容器启动时,它会执行以下命令:
1 /bin/ sh -c "touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600"
对于容器的前30秒,有一个/tmp/healthy文件。因此,在前30秒内,该命令cat /tmp/healthy返回成功代码。30秒后,cat /tmp/healthy返回失败代码。
在30秒内,查看Pod事件:
1 2 3 4 5 6 7 8 9 10 11 $ kubectl describe pod liveness- exec ...... ...... Events: Type Reason Age From Message Normal Scheduled 15 m default - scheduler Successfully assigned default / liveness- exec to k8s- m3 Normal Pulled 3 m (x3 over 5 m) kubelet, k8s- m3 Successfully pulled image "k8s.gcr.io/busybox" Normal Created 3 m (x3 over 5 m) kubelet, k8s- m3 Created container Normal Started 3 m (x3 over 5 m) kubelet, k8s- m3 Started container
在30秒后,查看Pod事件:
1 2 3 4 5 6 7 8 9 10 11 $ kubectl describe pod liveness- exec Events: Type Reason Age From Message Normal Scheduled 16 m default - scheduler Successfully assigned default / liveness- exec to k8s- m3 Normal Pulled 5 m (x3 over 7 m) kubelet, k8s- m3 Successfully pulled image "k8s.gcr.io/busybox" Normal Created 5 m (x3 over 7 m) kubelet, k8s- m3 Created container Normal Started 5 m (x3 over 7 m) kubelet, k8s- m3 Started container Warning Unhealthy 4 m (x9 over 7 m) kubelet, k8s- m3 Liveness probe failed: cat: can't open ' / tmp/ healthy': No such file or directory Normal Pulling 4m (x4 over 7m) kubelet, k8s-m3 pulling image "k8s.gcr.io/busybox" Normal Killing 2m (x4 over 6m) kubelet, k8s-m3 Killing container with id docker://liveness:Container failed liveness probe.. Container will be killed and recreated.
再等30秒,确认Container已重新启动, 下面输出中RESTARTS的次数已增加:
1 2 3 $ kubectl get pod liveness- exec NAME READY STATUS RESTARTS AGE liveness- exec 1 / 1 Running 1 1 m
示例二: 通过HTTP方式做健康探测 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 apiVersion: v1kind: Podmetadata: labels: test: liveness name: liveness-http spec: containers: - name: liveness image: k8s.gcr.io/liveness args: - /server livenessProbe: httpGet: path: /healthz port: 8080 httpHeaders: - name: X-Custom-Header value: Awesome initialDelaySeconds: 3 periodSeconds: 3
在配置文件中,使用k8s.gcr.io/liveness镜像,创建出一个Pod,其中periodSeconds字段指定kubelet每3秒执行一次探测,initialDelaySeconds字段告诉kubelet延迟等待3秒,探测方式为向容器中运行的服务发送HTTP GET请求,请求8080端口下的/healthz, 任何大于或等于200且小于400的代码表示成功。任何其他代码表示失败。
10秒后,查看Pod事件以验证liveness探测失败并且Container已重新启动:
1 2 3 $ kubectl describe pod liveness-http NAME READY STATUS RESTARTS AGEliveness-http 1 /1 RUNNING 1 1 m
httpGet探测方式有如下可选的控制字段
host:要连接的主机名,默认为Pod IP,可以在http request head中设置host头部。
scheme: 用于连接host的协议,默认为HTTP。
path:http服务器上的访问URI。
httpHeaders:自定义HTTP请求headers,HTTP允许重复headers。
port: 容器上要访问端口号或名称。
示例三:通过TCP方式做健康探测 Kubelet将尝试在指定的端口上打开容器上的套接字,如果能建立连接,则表明容器健康。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 apiVersion: v1 kind: Pod metadata: name: goproxy labels: app: goproxy spec: containers: - name: goproxy image: k8s.gcr.io/goproxy:0.1 ports: - containerPort: 8080 readinessProbe: tcpSocket: port: 8080 initialDelaySeconds: 5 periodSeconds: 10 livenessProbe: tcpSocket: port: 8080 initialDelaySeconds: 15 periodSeconds: 20
TCP检查方式和HTTP检查方式非常相似,示例中两种探针都使用了,在容器启动5秒后,kubelet将发送第一个readinessProbe探针,这将连接到容器的8080端口,如果探测成功,则该Pod将被标识为ready,10秒后,kubelet将进行第二次连接。
1 2 3 4 5 6 7 8 ports: - name: liveness-port containerPort: 8080 hostPort: 8080 livenessProbe: httpGet: path: /healthz port: liveness-port
ReadinessProbe探针配置: ReadinessProbe探针的使用场景livenessProbe稍有不同,有的时候应用程序可能暂时无法接受请求,比如Pod已经Running了,但是容器内应用程序尚未启动成功,在这种情况下,如果没有ReadinessProbe,则Kubernetes认为它可以处理请求了,然而此时,我们知道程序还没启动成功是不能接收用户请求的,所以不希望kubernetes把请求调度给它,则使用ReadinessProbe探针。
ReadinessProbe 探针探测容器是否已准备就绪,如果未准备就绪则kubernetes不会将流量转发给此Pod。
ReadinessProbe探针与livenessProbe一样也支持exec、httpGet、TCP的探测方式,配置方式相同,只不过是将livenessProbe字段修改为ReadinessProbe。
1 2 3 4 5 6 7 readinessProbe : exec : command : - cat - /tmp/healthy initialDelaySeconds : 5 periodSeconds : 5
示例一: ReadinessProbe示例 现在来看一个加入ReadinessProbe探针和一个没有ReadinessProbe探针的示例:
(感兴趣的同学可以了解一下,非常爽的一个自助gitweb平台Gogs )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 kind: Service apiVersion: v1 metadata: name: gogs namespace: default spec: selector: test: gogs ports: - protocol: TCP port: 3000 --- kind: Deployment apiVersion: apps/v1 metadata: name: gogs namespace: default spec: replicas: 1 selector: matchLabels: test: gogs template: metadata: labels: test: gogs spec: containers: - image: test imagePullPolicy: IfNotPresent name: gogs ports: - containerPort: 3000 affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - k8s-m1
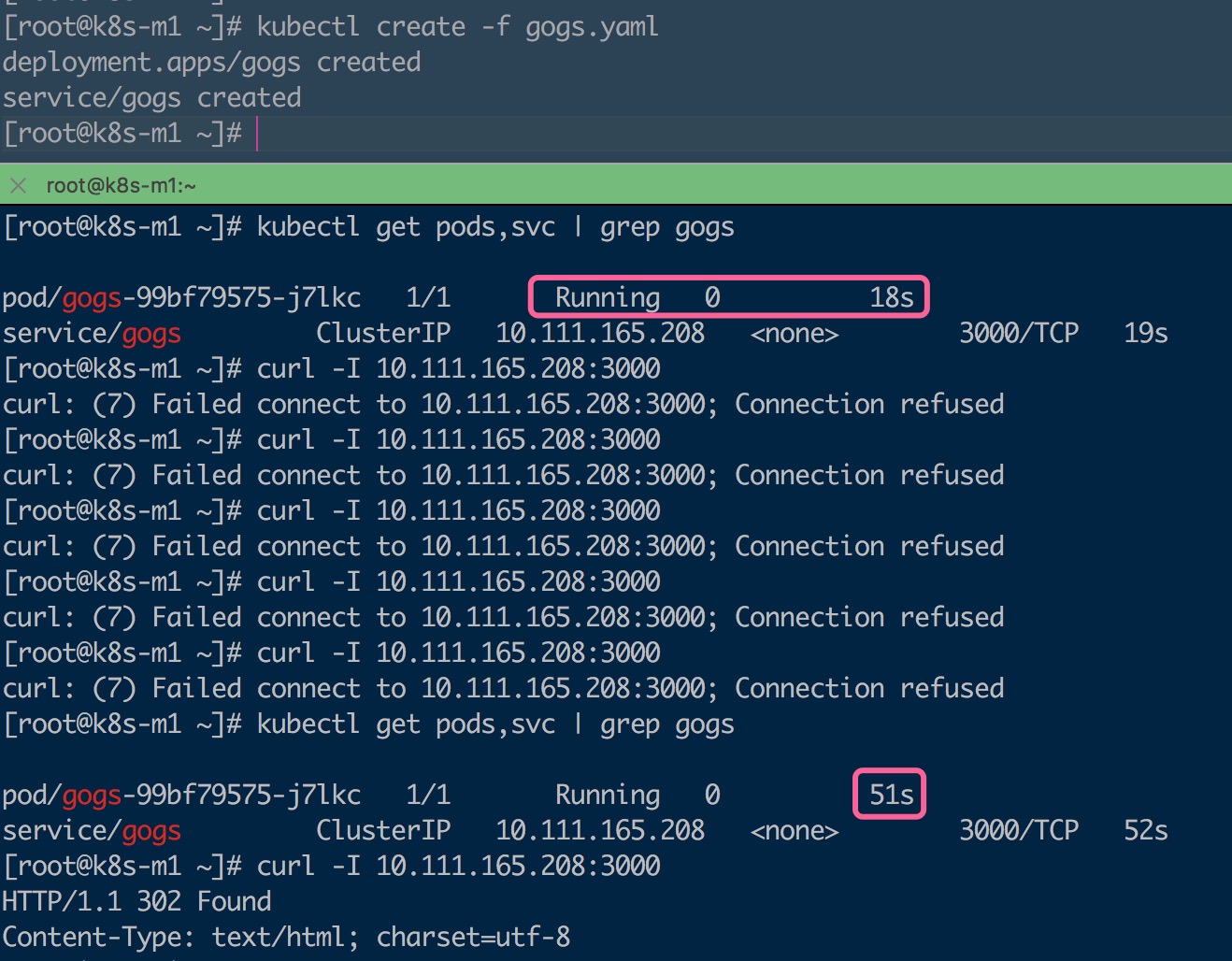
从上图可以看出来,当我创建部署之后,Pod启动18s,自身状态已Running,其READ字段,1/1 表示1个容器状态已准备就绪了,此时,对于kubernetes而言,它已经可以接收请求了,而实际上我在去访问的时候服务还无法访问,因为Gogo程序还尚启动起来,40s之后方可正常访问,所以针对于服务启动慢或者其他原因的此类程序,必须配置ReadinessProbe。
下面我加入readinessProbe
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 kind: Service apiVersion: v1 metadata: name: gogs namespace: default spec: selector: test: gogs ports: - protocol: TCP port: 3000 --- kind: Deployment apiVersion: apps/v1 metadata: name: gogs namespace: default spec: replicas: 1 selector: matchLabels: test: gogs template: metadata: labels: test: gogs spec: containers: - image: test imagePullPolicy: IfNotPresent name: gogs ports: - containerPort: 3000 readinessProbe: tcpSocket: port: 3000 initialDelaySeconds: 10 periodSeconds: 5 affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - k8s-m1

上图可以看出Pod虽然已处于Runnig状态,但是由于第一次探测时间未到,所以READY字段为0/1,即容器的状态为未准备就绪,在未准备就绪的情况下,其Pod对应的Service下的Endpoint也为空,所以不会有任何请求被调度进来。
当通过第一次探测的检查通过后,容器的状态自然会转为READ状态。
此后根据指定的间隔时间10s后再次探测,如果不通过,则kubernetes就会将Pod IP从EndPoint列表中移除。
配置探针(Probe)相关属性 探针(Probe)有许多可选字段,可以用来更加精确的控制Liveness和Readiness两种探针的行为(Probe):
initialDelaySeconds:Pod启动后延迟多久才进行检查,单位:秒。periodSeconds:检查的间隔时间,默认为10,单位:秒。timeoutSeconds:探测的超时时间,默认为1,单位:秒。successThreshold:探测失败后认为成功的最小连接成功次数,默认为1,在Liveness探针中必须为1,最小值为1。failureThreshold:探测失败的重试次数,重试一定次数后将认为失败,在readiness探针中,Pod会被标记为未就绪,默认为3,最小值为1。
参考:https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-probes/
 wechat
wechat alipay
alipay




