概述 首先需要了解这三种机制的区别:
认证(Authenticating)是对客户端的认证,通俗点就是用户名密码验证,
授权(Authorization)是对资源的授权,k8s中的资源无非是容器,最终其实就是容器的计算,网络,存储资源,当一个请求经过认证后,需要访问某一个资源(比如创建一个pod),授权检查都会通过访问策略比较该请求上下文的属性,(比如用户,资源和Namespace),根据授权规则判定该资源(比如某namespace下的pod)是否是该客户可访问的。
准入(Admission Control)机制是一种在改变资源的持久化之前(比如某些资源的创建或删除,修改等之前)的机制。
kubernetes 中的认证机制 需要注意的是,kubernetes虽然提供了多种认证机制,但并没有提供user 实体信息的存储,也就是说,账户体系需要我们自己去做维护。当然,也可以接入第三方账户体系(如谷歌账户),也可以使用开源的keystone去做整合。kubernetes 支持多种认证机制,可以配置成多个认证体制共存,这样,只要有一个认证通过,这个request就认证通过了。下面列举的是官网几种常见认证机制:
X509 Client Certs
Static Token File
Bootstrap Tokens
Static Password File
Service Account Tokens
OpenID Connect Tokens
这里我主要还是理解一下常用认证方式:
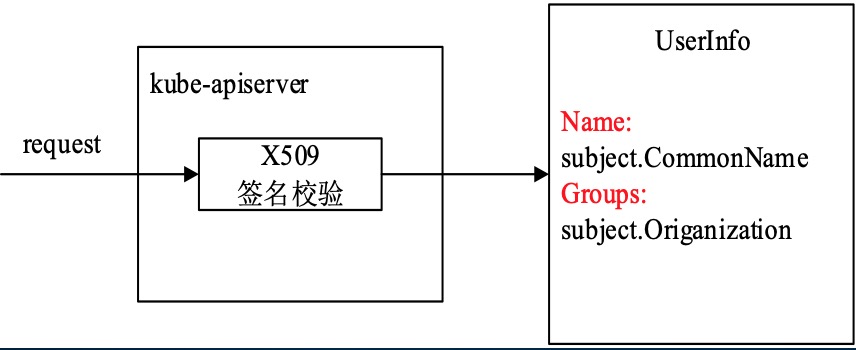
X509 Client Certs 也叫作双向数字证书认证,HTTPS证书认证,是基于CA根证书签名的双向数字证书认证方式,是所有认证方式中最严格的认证。默认在kubeadm创建的集群中是enabled的,可以在master node上查看kube-apiserver的pod配置文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 $ cat /usr/lib/systemd/system/kube-apiserver.service .. .. .. .. .. .. .. .. .. .. ExecStart =/usr/local/bin/kube-apiserver \ --v =2 \ --logtostderr =true \ --allow-privileged =true \ --bind-address =0.0.0.0 \ --secure-port =6443 \ --insecure-port =0 \ --advertise-address =192.168.56.110 \ --service-cluster-ip-range =10.96.0.0/12 \ --service-node-port-range =30000-32767 \ --etcd-servers =https://192.168.56.111:2379,https://192.168.56.112:2379,https://192.168.56.113:2379 \ --etcd-cafile =/etc/etcd/ssl/etcd-ca.pem \ --etcd-certfile =/etc/etcd/ssl/etcd.pem \ --etcd-keyfile =/etc/etcd/ssl/etcd-key.pem \ --client-ca-file =/etc/kubernetes/pki/ca.pem \ --tls-cert-file =/etc/kubernetes/pki/apiserver.pem \ --tls-private-key-file =/etc/kubernetes/pki/apiserver-key.pem \ --kubelet-client-certificate =/etc/kubernetes/pki/apiserver.pem \ --kubelet-client-key =/etc/kubernetes/pki/apiserver-key.pem \ .. .. .. .. .. .. .. .. .. ..
相关的三个启动参数:
client-ca-file: 指定CA根证书文件为/etc/kubernetes/pki/ca.pem
tls-private-key-file: 指定ApiServer私钥文件为/etc/kubernetes/pki/apiserver-key.pem
tls-cert-file:指定ApiServer证书文件为/etc/kubernetes/pki/apiserver.pem
请求中需要带有由该证书签名的证书,才能认证通过,客户端签署的证书里包含user,group信息,具体为证书的subject.CommonName(username)以及subject.Organization(group)
Service Account Tokens Service Account Token 是一种比较特殊的认证机制,适用于上文中提到的pod内部服务需要访问apiserver的认证情况,默认enabled。
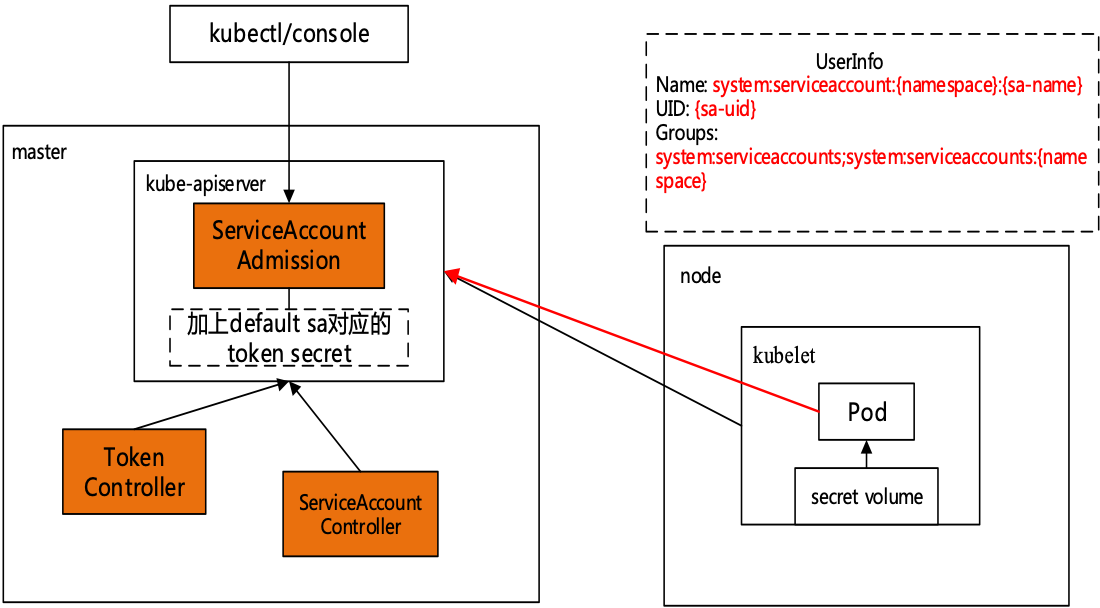
通过控制器ServiceAccountController会去list,watch k8s apiserver对于命名空间的创建、删除;
TokenController 根据创建的ServiceAccount下面关联生成一个带有Token的secret。
service accout本身是作为一种资源在k8s集群中,我们可以通过命令行获取
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 $ kubectl get sa - -all-namespaces NAMESPACE NAME SECRETS AGE default default 1 16 d kube-system default 1 16 d kube-public default 1 16 d kube-system attachdetach-controller 1 16 d kube-system bootstrap-signer 1 16 d kube-system calico-node 1 16 ........... ........... $ kubectl describe serviceaccount/default - n kube-system Name: defaultNamespace: kube-systemLabels: <none> Annotations: <none> Image pull secrets: <none> Mountable secrets: default-token-q9s9l Tokens: default-token-q9s9lEvents: <none> $ kubectl get secret default-token-q9s9l - o yaml - n kube-system apiVersion: v1data: ca.crt: LS0tLS1CRUdJ ...............略 namespace: a3ViZS1zeXN0ZW0= token: ZXlKaGJHY2lPaUpTVX- ...............略 kind: Secretmetadata: annotations: kubernetes.io/ service-account.name: default kubernetes.io/ service-account.uid: a5568634-f445-11 e8-b4c4-000 c295134cf creationTimestamp: 201 8-1 1-30 T02:14 :19 Z name: default-token-q9s9l namespace: kube-system resourceVersion: "337" selfLink: /api/v1/namespaces/kube-system/secrets/default-token-q9s9l uid: a56521fd-f445-11 e8-aa44-000 c29fe5618 type: kubernetes.io/service-account-token [root@k8s-m1 kubelet]
可以看到service-account-token的secret资源包含的数据有三部分:
ca.crt,这是API Server的CA公钥证书,用于Pod中的Process对API Server的服务端数字证书进行校验时使用的;
namespace,这是Secret所在namespace的值的base64编码:# echo -n “kube-system”|base64 => “a3ViZS1zeXN0ZW0=”
token:该token就是由service-account-key-file的值签署(sign)生成。
API Server的service account authentication(身份验证) 前面说过,service account为Pod中的Process提供了一种身份标识,在Kubernetes的身份校验(authenticating)环节,以某个service account提供身份的Pod的用户名为:
1 system: serviceaccount:(NAMESPACE ):(SERVICEACCOUNT)
以上面那个kube-system namespace下的default service account为例,使用它的Pod的username全称为:
1 system :serviceaccount:kube-system :default
默认的service account Kubernetes会为每个cluster中的namespace自动创建一个默认的service account资源,并命名为”default”.
如果Pod中没有显式指定spec.serviceAccount字段值(自定义Admission),那么Kubernetes会默认将该namespace下的default service account自动mount到在这个namespace中创建的Pod里,那这个操作就是通过上面所说的ServiceAccountAdmission来实现的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 $ kubectl describe pod nginx-64 f497f8fd-lkmdr Name: nginx-64 f497f8fd-lkmdr Namespace: default ... ... ... ... Containers: ... ... ... ... Mounts: /var /run/secrets/kubernetes.io/serviceaccount from default-token -d5d8g (ro) Conditions: Type Status Initialized True Ready False ContainersReady False PodScheduled True Volumes: ... ... ... ... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 27 s default-scheduler Successfully assigned default/nginx-64 f497f8fd-lkmdr to k8s-m3 Normal Pulling 17 s kubelet, k8s-m3 pulling image "nginx"
可以看到,kubernetes将default namespace中的service account “default”的service account token挂载(mount)到了Pod中容器的/var/run/secrets/kubernetes.io/serviceaccount路径下。
深入容器内部,查看mount的serviceaccount路径下的结构:
1 2 3 4 5 6 $ kubectl exec nginx-64f497f8fd-lkmdr -- ls /var /run /secrets/kubernetes.io/serviceaccount ca .crtnamespace token # 这三个文件与上面提到的service account的token 中的数据是一一对应的。
如何创建一个ServiceAccount 1 2 3 4 5 6 7 8 9 10 11 12 13 14 $ kubectl create sa myk8ssa serviceaccount/myk8ssa created $ kubectl describe sa/myk8ssa Name: mysaNamespace: defaultLabels: <none> Annotations: <none> Image pull secrets: <none> Mountable secrets: mysa-token-kcwqm Tokens: mysa-token-kcwqmEvents: <none>
kubernetes 中的鉴权机制 目前,k8s 中一共有 4 种鉴权权限模式:
Node: 一种特殊目的的授权模式,主要用来让 kubernetes 遵从 node 的编排规则,实际上是 RBAC 的一部分,相当于只定义了 node 这个角色以及它的权限;
ABAC: Attribute-based access control;
RBAC: Role-based access control;
Webhook: 以 HTTP Callback 的方式,利用外部授权接口来进行权限控制;
这里我主要学习总结最常用的鉴权方式—RBAC
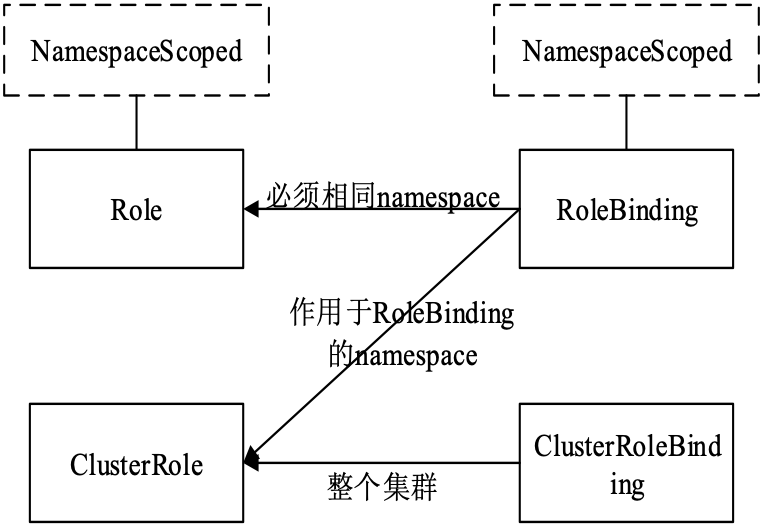
需要理解 RBAC 一些基础的概念和思路,RBAC 是让用户能够访问 Kubernetes API 资源的授权方式。
role role binding
另外还要考虑cluster roles和cluster role binding。cluster role和cluster role binding方法跟role和role binding一样,出了它们有更广的scope。
Kubernetes中的RBAC
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 $ kubectl get clusterroles --namespace=kube-system NAME AGE admin 16d anonymous-dashboard-proxy-role 16d calico-node 16d calicoctl 16d cluster-admin 16d edit 16d system: aggregate-to-admin 16d system: aggregate-to-edit 16d system: aggregate-to-view 16d system: auth-delegator 16d system: aws-cloud-provider 16d system: basic-user 16d system: certificates. k8s. io:certificatesigningrequests:nodeclient 16d system: certificates. k8s. io:certificatesigningrequests:selfnodeclient 16d system: controller:attachdetach-controller 16d system: controller:certificate-controller 16d system: controller:clusterrole-aggregation-controller 16d system: controller:cronjob-controller 16d system: controller:daemon-set-controller 16d system: controller:deployment-controller 16d system: controller:disruption-controller 16d system: controller:endpoint-controller 16d system: controller:expand-controller 16d ......略
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 $ cat > > role.yaml < < EOF kind: RoleapiVersion: rbac.authorization.k8s.io/v1 metadata: namespace: default name: pod-reader rules: - apiGroups: ["" ] resources: ["pods" ] verbs: ["get" , "watch" , "list" ] EOF $ cat > > rolebinding.yaml < < EOF kind: RoleBindingapiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: pod-reader-binding namespace: default subjects: - kind: ServiceAccount name: mysa namespace: default roleRef: kind: Role name: pod-reader apiGroup: rbac.authorization.k8s.io EOF $ kubectl create - f role.yaml role.rbac.authorization.k8s.io/pod-reader created $ kubectl create - f rolebinding.yaml rolebinding.rbac.authorization.k8s.io/pod-reader-binding created [root@k8s-m1 ~] NAME AGE pod-reader 36 s [root@k8s-m1 ~] Name: pod-readerLabels: <none> Annotations: <none> PolicyRule: Resources Non-Resource URLs Resource Names Verbs - -------- - ---------------- - ------------- - ---- pods [] [] [get watch list] $ kubectl describe rolebinding pod-reader-binding Name: pod-reader-bindingLabels: <none> Annotations: <none> Role: Kind: Role Name: pod-reader Subjects: Kind Name Namespace - --- - --- - -------- ServiceAccount mysa default
上面,
我定义了一个pod-reader的role,其中它的权限定义如上方定义的get,watch,list;
然后定义了一个pod-reader-binding的rolebinding
那如何使用我们自己创建的ServiceAccount来登录并且通过自定义的这个RBAC来鉴权呢?这就涉及到了kubeconfig文件生成的问题了
创建kubeconfig 获取上面已创建的ServiceAccount的Seter名称 这里我是在默认namespace下面创建的。
1 2 3 4 5 6 7 8 9 $ kubectl describe sa/myk8ssa Name: myk8ssaNamespace: defaultLabels: <none> Annotations: <none> Image pull secrets: <none> Mountable secrets: myk8ssa-token-2 kntd Tokens: myk8ssa-token-2 kntdEvents: <none>
获取secret下的token,并base64解码获取token明文 1 2 3 $ token =`kubectl get secret myk8ssa-token-2kntd -oyaml |grep token: | awk '{print $2}' | xargs echo -n | base64 -d` $ echo $token eyJhbGciOiJSUzI1.. .. .. 略
新增用户guomaoqiu 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 $ kubectl config set-cluster my-k8s --server=https://192.168.56.110:8443 \ --certificate-authority=/etc/kubernetes/pki/ca.pem \--embed-certs=true Cluster "my-k8s" set .$ kubectl config set-credentials guomaoqiu --token=$token User "guomaoqiu" set .$ kubectl config set-context my-k8s --cluster=kubernetes Context "my-k8s" created .$ kubectl config set-context my-k8s --user=guomaoqiu Context "my-k8s" modified .
验证 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 $ kubectl config get-contexts CURRENT NAME CLUSTER AUTHINFO NAMESPACE kubernetes-admin@kubernetes kubernetes kubernetes-admin * my-k8s kubernetes guomaoqiu$ kubectl config use-context my-k8s Switched to context "my-k8s" . $ kubectl get pod NAME READY STATUS RESTARTS AGE nginx-64 f497f8fd-4 qdnt 1 /1 Running 0 10 m $ kubectl delete pod nginx-64 f497f8fd-4 qdnt Error from server (Forbidden): pods "nginx-64f497f8fd-4qdnt" is forbidden: User "system:serviceaccount:default:myk8ssa" cannot delete pods in the namespace "default" $ kubectl config view apiVersion: v1clusters: - cluster: certificate-authority-data: REDACTED server: https:// 192.168 .56.110 :8443 name: kubernetes - cluster: certificate-authority-data: REDACTED server: https:// 192.168 .56.110 :8443 name: my-k8s contexts: - context: cluster: kubernetes user: kubernetes-admin name: kubernetes-admin@kubernetes - context: cluster: kubernetes user: guomaoqiu name: my-k8s current-context: my-k8s kind: Configpreferences: {}users: - name: guomaoqiu user: token:......略 - name: kubernetes-admin user: client-certificate-data: REDACTED client-key-data: REDACTED
通过namespace我们可以做到不同业务之间的隔离,如果再加上如上这种权限控制将会更加细化、以上实验主要是在默认的namespace下面操作,除此之外也可以新建namespace然后进行验证操作。kubeconfig切换上下文也是非常实用的一种功能。
1 2 3 4 5 6 7 8 kubectl - 使用kubectl 来管理Kubernetes 集群。kubectl config set - 在kubeconfig 配置文件中设置一个单独的值。kubectl config set-cluster - 在kubeconfig 配置文件中设置一个集群项。kubectl config set-context - 在kubeconfig 配置文件中设置一个环境项。kubectl config set-credentials - 在kubeconfig 配置文件中设置一个用户项。kubectl config unset - 在kubeconfig 配置文件中清除一个单独的值。kubectl config use-context - 使用kubeconfig 中的一个环境项作为当前配置。kubectl config view - 显示合并后的kubeconfig 设置,或者一个指定的kubeconfig 配置文件。
kubernetes 中的准入机制 Kubernetes的Admission Control实际上是一个准入控制器(Admission Controller)插件列表,发送到APIServer的请求都需要经过这个列表中的每个准入控制器插件的检查,如果某一个控制器插件准入失败,就准入失败。http://docs.kubernetes.org.cn/144.html PodSecurityPolicy
安全上下文(Pod SecurityContext) 分为Pod级别和容器级别,容器级别的会覆盖Pod级别的相同设置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 cat > > pod-security-policy.yaml < < EOF apiVersion: v1kind: Podmetadata: name: test-pod spec: volumes: - name: test emptyDir: {} containers: - name: test-pod image: alpine imagePullPolicy: IfNotPresent command: ['sh', '-c', 'echo The app is running! && sleep 36000 '] volumeMounts: - name: test mountPath: /data/test securityContext: readOnlyRootFilesystem: false privileged: false runAsUser: 1000 EOF $ kubectl create - f pod-security-policy.yaml pod/test-pod created $ kubectl exec - it test-pod sh / $ iduid = 1000 gid= 0 (root) / $ ps - efPID USER TIME COMMAND 1 1000 0 :00 sleep 36000 6 1000 0 :00 sh 15 1000 0 :00 sh 21 1000 0 :00 ps - ef / $ sysctl - w net.ipv4.tcp_recovery= 2 sysctl: error setting key 'net.ipv4.tcp_recovery': Read-only file system/ $
其他更多参数参见: https://kubernetes.io/docs/concepts/policy/pod-security-policy/
运行态的安全控制—网络策略(NetworkPolicy) Kubernetes要求集群中所有pod,无论是节点内还是跨节点,都可以直接通信,或者说所有pod工作在同一跨节点网络,此网络一般是二层虚拟网络,称为pod网络。在安装引导kubernetes时,由选择并安装的network plugin实现。默认情况下,集群中所有pod之间、pod与节点之间可以互通。
网络主要解决两个问题,一个是连通性,实体之间能够通过网络互通。另一个是隔离性,出于安全、限制网络流量的目的,又要控制实体之间的连通性。Network Policy用来实现隔离性,只有匹配规则的流量才能进入pod,同理只有匹配规则的流量才可以离开pod。
但请注意,kubernetes支持的用以实现pod网络的network plugin有很多种,并不是全部都支持Network Policy,为kubernetes选择network plugin时需要考虑到这点,是否需要隔离?可用network plugin及是否支持Network Policy请参考这里 。
基本原理 Network Policy是kubernetes中的一种资源类型,它从属于某个namespace。其内容从逻辑上看包含两个关键部分,一是pod选择器,基于标签选择相同namespace下的pod,将其中定义的规则作用于选中的pod。另一个就是规则了,就是网络流量进出pod的规则,其采用的是白名单模式,符合规则的通过,不符合规则的拒绝。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 apiVersion: networking.k8s.io/v1 kind: NetworkPolicymetadata: name: test-network-policy namespace: default spec: podSelector: matchLabels: role: db policyTypes: - Ingress - Egress ingress: - from: - ipBlock: cidr: 172.17 .0.0 /16 except: - 172.17 .1.0 /24 - namespaceSelector: matchLabels: project: myproject - podSelector: matchLabels: role: frontend ports: - protocol: TCP port: 6379 egress: - to: - ipBlock: cidr: 10.0 .0.0 /24 ports: - protocol: TCP
对象创建方法与其它如ReplicaSet相同。apiVersion、kind、metadata与其它类型对象含义相同,不详细描述。
.spec.PodSelector
.spec.PolicyTypes
.spec.ingress与.spec.egress
.spec.egress.to 定义的是pod想要访问的外部destination,其它与ingress相同。
kubernetes 默认NetworkPolicy: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 apiVersion : networking.k8s.io/v1 kind : NetworkPolicy metadata : name : default-deny spec : podSelector : {} policyTypes : - Egress apiVersion : networking.k8s.io/v1 kind : NetworkPolicy metadata : name : default-deny spec : podSelector : {} policyTypes : - Ingress apiVersion : networking.k8s.io/v1 kind : NetworkPolicy metadata : name : allow-all spec : podSelector : {} egress : - {} policyTypes : - Egress apiVersion : networking.k8s.io/v1 kind : NetworkPolicy metadata : name : allow-all spec : podSelector : {} egress : - {} policyTypes : - Ingress
默认策略 无需详解,但请注意,pod与所运行节点之间流量不受Network Policy限制。
示例 下面通过一个真实示例展示Network Policy普通用法。
用Deployment创建nginx pod实例并用service暴露 1 2 3 4 $ kubectl run nginx --image =nginx --replicas =3 deployment.apps/nginx created $ kubectl expose deployment nginx --port =80 service/nginx exposed
确认创建结果 1 2 3 4 5 6 7 8 9 $ kubectl get pod,svc NAME READY STATUS RESTARTS AGE pod/nginx-64f497f8fd-9mfd7 1 /1 Running 0 2 m pod/nginx-64f497f8fd-nss94 1 /1 Running 0 2 m pod/nginx-64f497f8fd-zs926 1 /1 Running 0 2 m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/kubernetes ClusterIP 10.96 .0.1 <none> 443 /TCP 3 d service/nginx ClusterIP 10.111 .254.191 <none> 80 /TCP 14 s
测试nginx服务连通性 1 2 3 4 5 $ kubectl run busybox --rm -it --image=busybox /bin/sh If you don't see a command prompt, try pressing enter. / Connecting to nginx (10.111.254.191:80) /
通过创建Network Policy对象添加隔离性 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 $ cat > > pod-network-policy.yaml < < EOF kind: NetworkPolicyapiVersion: networking.k8s.io/v1 metadata: name: access-nginx spec: podSelector: matchLabels: run: nginx ingress: - from: - podSelector: matchLabels: access: "true" EOF $ kubectl create - f pod-network-policy.yaml networkpolicy.networking.k8s.io/access-nginx created $ kubectl describe networkpolicy access-nginx Name: access-nginxNamespace: defaultCreated on: 201 8-1 2-17 01 :16 :57 - 0500 EST Labels: <none> Annotations: <none> Spec: PodSelector: run= nginx Allowing ingress traffic: To Port: <any> (traffic allowed to all ports) From: PodSelector: access= true Allowing egress traffic: <none> (Selected pods are isolated for egress connectivity) Policy Types: Ingress
测试隔离性 1 2 3 4 5 $ kubectl run busybox --rm -it --image=busybox /bin/sh If you don't see a command prompt, try pressing enter. / Connecting to nginx (10.111.254.191:80) wget: download timed out
为pod添加access: “true”标签后再次测试连通性 1 2 3 4 $ kubectl run busybox --rm -it --labels= "access=true" --image=busybox /bin/sh If you don't see a command prompt, try pressing enter. / Connecting to nginx (10.111.254.191:80)
参考:https://kubernetes.io/docs/tasks/configure-pod-container/configure-service-account/ https://kubernetes.io/docs/reference/access-authn-authz/rbac/ https://kubernetes.io/docs/concepts/services-networking/network-policies/ https://kubernetes.io/docs/tasks/access-application-cluster/configure-access-multiple-clusters/ https://kubernetes.io/docs/concepts/policy/pod-security-policy/

 wechat
wechat alipay
alipay









